OpenMP安装
1 | $ brew install libomp #最新版MacOSX只需要安装即可使用 |
配置Clion
Preferences -> Build,Execution,Deployment -> Toolchains中新建一个用户配置,设置对应的cmake,make,C/C++ compiler
Preferences -> Build,Execution,Deployment -> CMake中Toolchain选择自己所配置的新用户
CMakeLists.txt如何配置
1 | cmake_minimum_required(VERSION 3.13.2) |
如果只使用C++,则只配置了项目的CXX属性,并忽略C编译器的配置
OpenMP使用
常用函数
1 | #返回当前可用的处理器个数 |
parallel和for循环
检查对OpenMP的支持
1 | #ifndef _OPENMP |
声明
第二种声明方式简洁,但第一种声明方式可以在for循环以外写其他并行代码
1 | //声明方式一 |
for循环并行化约束条件
- for循环中的循环变量必须是有符号整形
- for循环中比较操作符必须是<, <=, >, >=
- for循环中的第三个表达式,必须是整数加减,并且加减值必须是一个循环不变量,且只能是自操作,如++,–,+=,-=
- 如果for循环中的比较操作为<或<=,那么循环变量只能增加;反之亦然
- 循环必须是单入口、单出口,也就是说循环内部不允许能够达到循环以外的跳转语句,exit除外. 异常的处理也必须在循环体内处理
数据共享与私有化
除了以下三种情况外,并行区域中的所有变量都是共享的:
- 并行区域中定义的变量
- 多个线程用来完成循环的循环变量
- private、firstprivate、lastprivate或reduction字句修饰的变量
1 | int share_to_private_b = 1; |
1 | #如果使用private,无论该变量在并行区域外是否初始化,在进入并行区域后,该变量均不会初始化 |
reduction
1 | #pragma omp parallel for reduction(+:sum) |
reduction(operator: var1, val2, …)
其中operator以及约定变量的初始值如下:
| 运算符 | 数据类型 | 默认初始值 |
|---|---|---|
| +/- | 整数、浮点 | 0 |
| * | 整数、浮点 | 1 |
| & | 整数 | 所有位均为1 |
| | | 整数 | 0 |
| ^ | 整数 | 0 |
| && | 整数 | 1 |
| || | 整数 | 0 |
线程同步atomic
1 | #pragma omp atomic |
atomic只能用于两种情况(单变量的自操作,跟for中介绍的一样):
- 自加自减:x++, x–, –x, ++x
- x< + or * or - or / or & or | or << or >> >=expr,(例如x <<= 1; or x *=2;)
线程同步critical
critical用途类似java中的synchronized
1 | #pragma omp critical[(name)] //[]表示名字可选 |
线程事件同步机制
隐式屏障
barrier为隐式栅障,即并行区域中所有线程执行完毕之后,主线程才继续执行。可以显示调用
1 | //在两个for循环中添加 |
nowait取消栅障
1 | #pragma omp for nowait //不能用#pragma omp parallel for nowait |
master
通过#pragma omp mater来声明对应的并行程序块只由主线程完成
1 | #pragma omp master |
section
1 | #pragma omp parallel sections |
调度
1 | #pragma omp parallel for schedule(kind [, chunk size]) |
kind: static, dynamic, guided, runtime(runtime没有chunk size)
了解OpenMPI
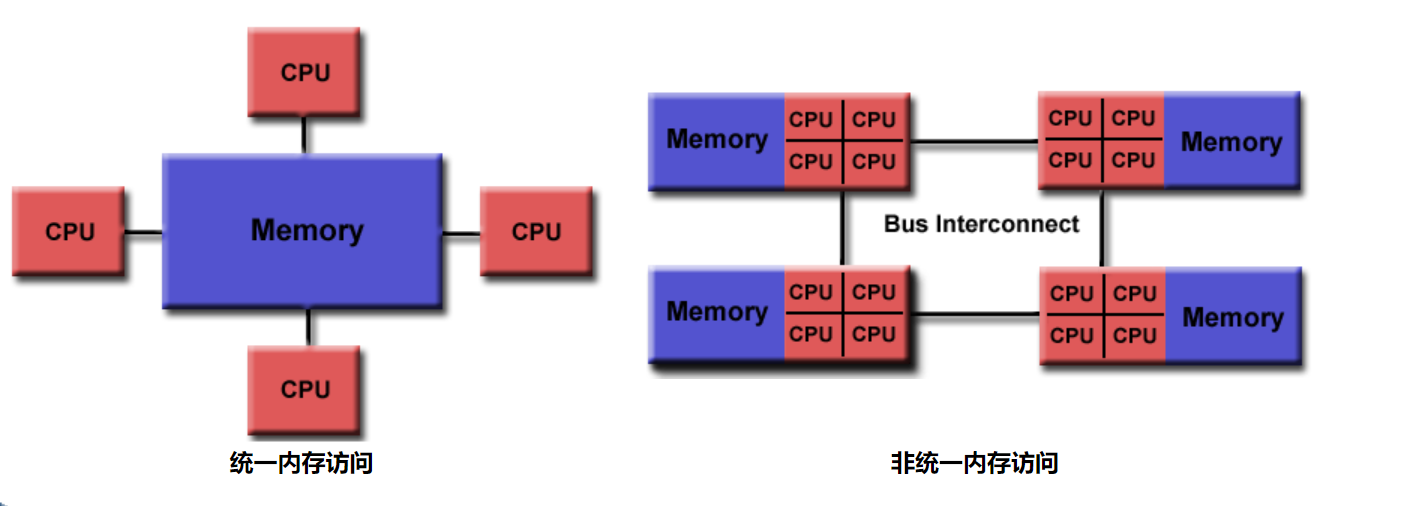
OpenMPI与OpenMP完全不一样。OpenMPI意义在于多机多硬件架构,OpenMP在于SMP(UMA)架构或者NUMA架构。
OpenMPI安装
1 | $ brew install open-mpi |
CLion配置
Preferences -> Build,Execution,Deployment -> Toolchains中新建一个用户配置,设置对应的cmake,make,C/C++ compiler(配置为mpic++/mpicc)
Preferences -> Build,Execution,Deployment -> CMake中Toolchain选择自己所配置的新用户
CMakeLists.txt如何配置
1 | cmake_minimum_required(VERSION 3.13.2) |
编译运行
示例见参考文献[3].
编译如下:
1 | $ mpicc -o mpi_hello_world main.cpp |