Raft
1. 基本介绍
- Raft算法解决Log Duplicate问题。
- Raft选举使用随机时间等待来防止进入多候选人选票瓜分的情况。
- Raft只有过半原则决策保持了与Paxos一致,过半原则在日志复制和Leader宕机后,根据entry是否被提交,起到相当关键的作用。在Leader宕机之后的选举中,entry是否被提交,对新Leader的产生起到了关键性的影响。
- Raft算法对Leader宕机或连续宕机时的安全性(正确性)、集群成员变化时的过渡机制、日志快照,进行了特别的算法解释。
2. 具体的解释
- Election 正确性的保证?时间要求
1 | 广播时间(broadcastTime) << 选举超时时间(electionTimeout) << 平均故障间隔时间(MTBF) |
关于日志复制:正确性如何保证?
Raft一致性算法原则的总结:选举安全、Leader只附加、日志匹配、Leader完全特性、状态机安全。其中Leader完全特性和日志匹配是保证正确性的关键原则。

Raft永远不会提交一个之前任期内的日志条目。通过选举出具有正确性的最超前状态Node作为Leader,只有Leadr当前任期里的日志条目可以被提交;一旦当前任期的日志条目以这种方式被提交,那么由于日志匹配特性,之前的日志条目也都会被间接的提交。
宕机之后再选举的数据安全性保证:保证具有最前沿状态的server被选为Leader:
检查term ——> 检查nextIndex/prevLogIndex ——> 检查commitIndex
集群成员变化: 如何自动化过渡?
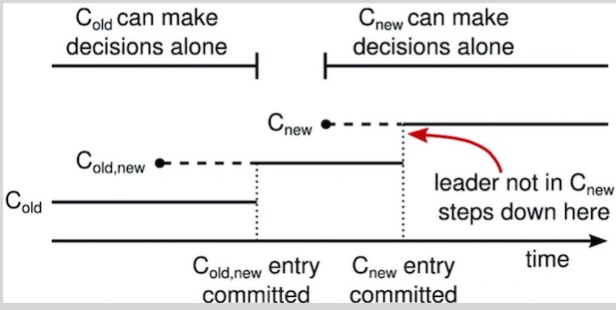
成员变化时,Leader要使用C-old,new的规则来决定日志条目C-old,new什么时候需要被提交。即,既满足C-old的提交条件,亦满足C-new的提交条件。假设现在是增加成员变量,C-old的提交状态肯定是C-new提交状态的一个包含集。
一旦C-old,new被提交,无论是C-old还是C-new,都不可能单独做出决定,并且Leader完全特性保证了只有拥有C-old,new日志条目的服务器才有可能被选举为Leader。
状态参考:
日志快照
每个服务器==独立的==创建快照,只包括已经被提交的日志。主要的工作包括将状态机的状态写入到快照中。
Raft包含一些少量的元数据到快照中:last included index指是被快照取代的最后的条目在日志中的索引值(状态机最后应用的日志), last included term指该条目的任期号。
客户端交互:保证不可读出脏数据?
Leader必须有关于被提交日志的最新信息。Raft通过Leader在任期开始时提交一个空白的没有任何操作的日志条目到日志中去来实现。
Leader在处理只读请求前必须检查自己是否已经被废止。Raft通过让领导人在响应只读请求之前,先和集群中的大多数Node交换一次心跳来处理这个问题。
Referance:
- Raft论文 英文版
- Raft论文 中文翻译 :此翻译不精确,推荐参照英文原文对比理解
- Raft官网
- Raft动画演示