Architecture
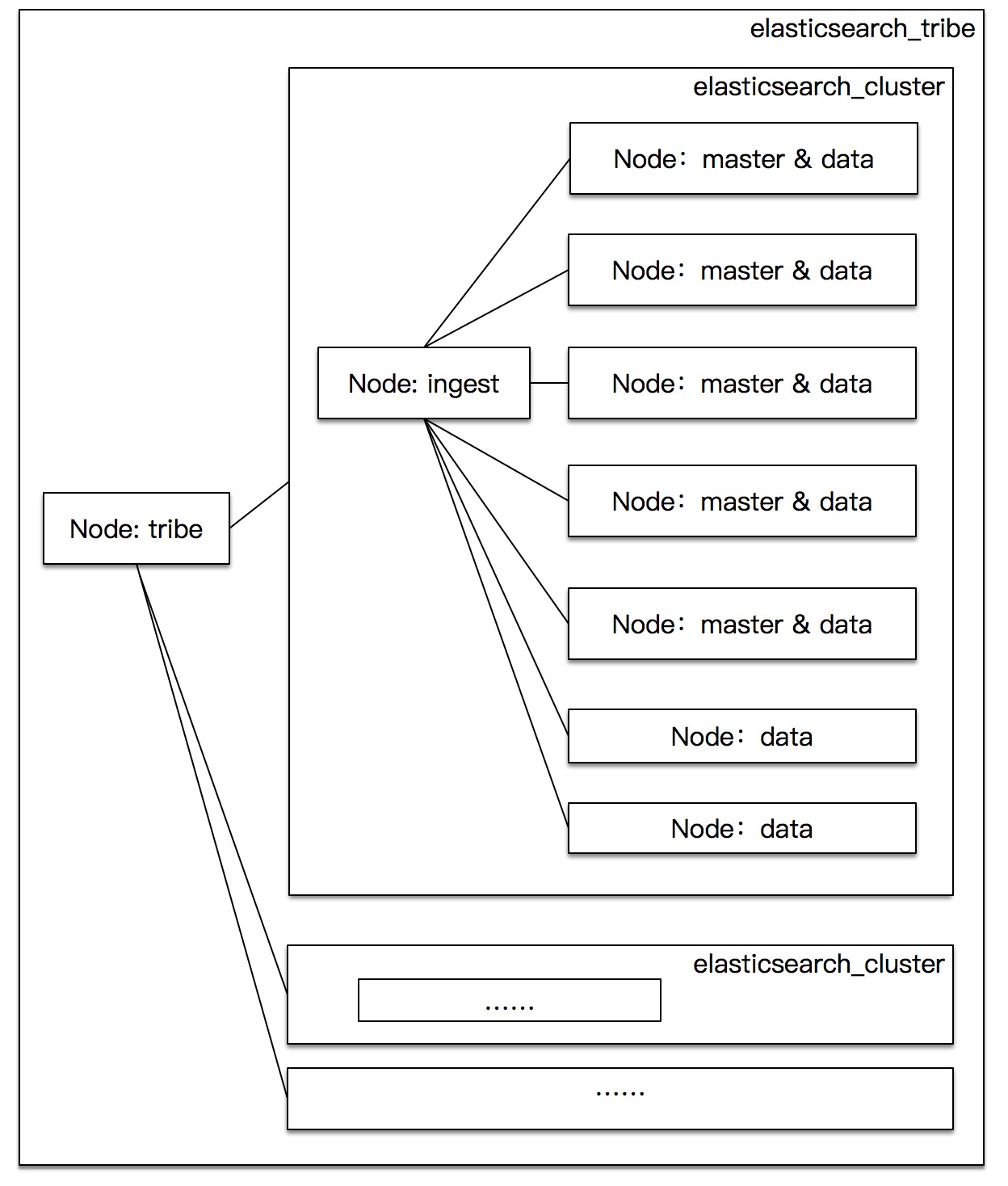
- Elasticsearch Arch:
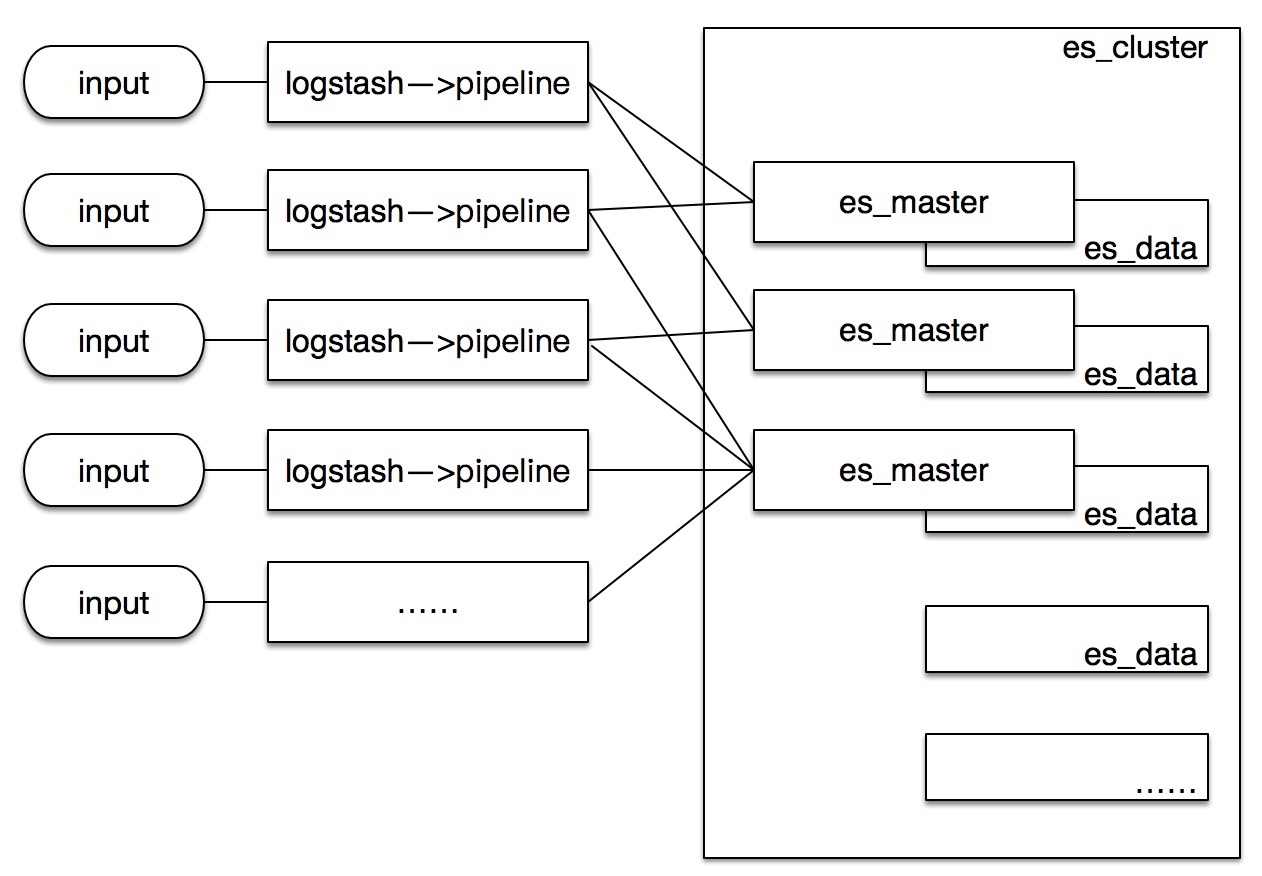
- Logstash:
每个logstash都是独立的进程,每机可开多个logstash运行,logstash之间没有需要协同工作的状态,属于单机运行程序。
- Kibana:
Kibana是用nodejs开发的web界面,其中如果开启Kibana,kibana会在elasticsearch中生成一个指定名配置的名的索引,因而如果多个kibana连接多台es_master机器,所图标等的保存也会被记录下来。
工作图:kibana => elasticsearch
- Elk Arch
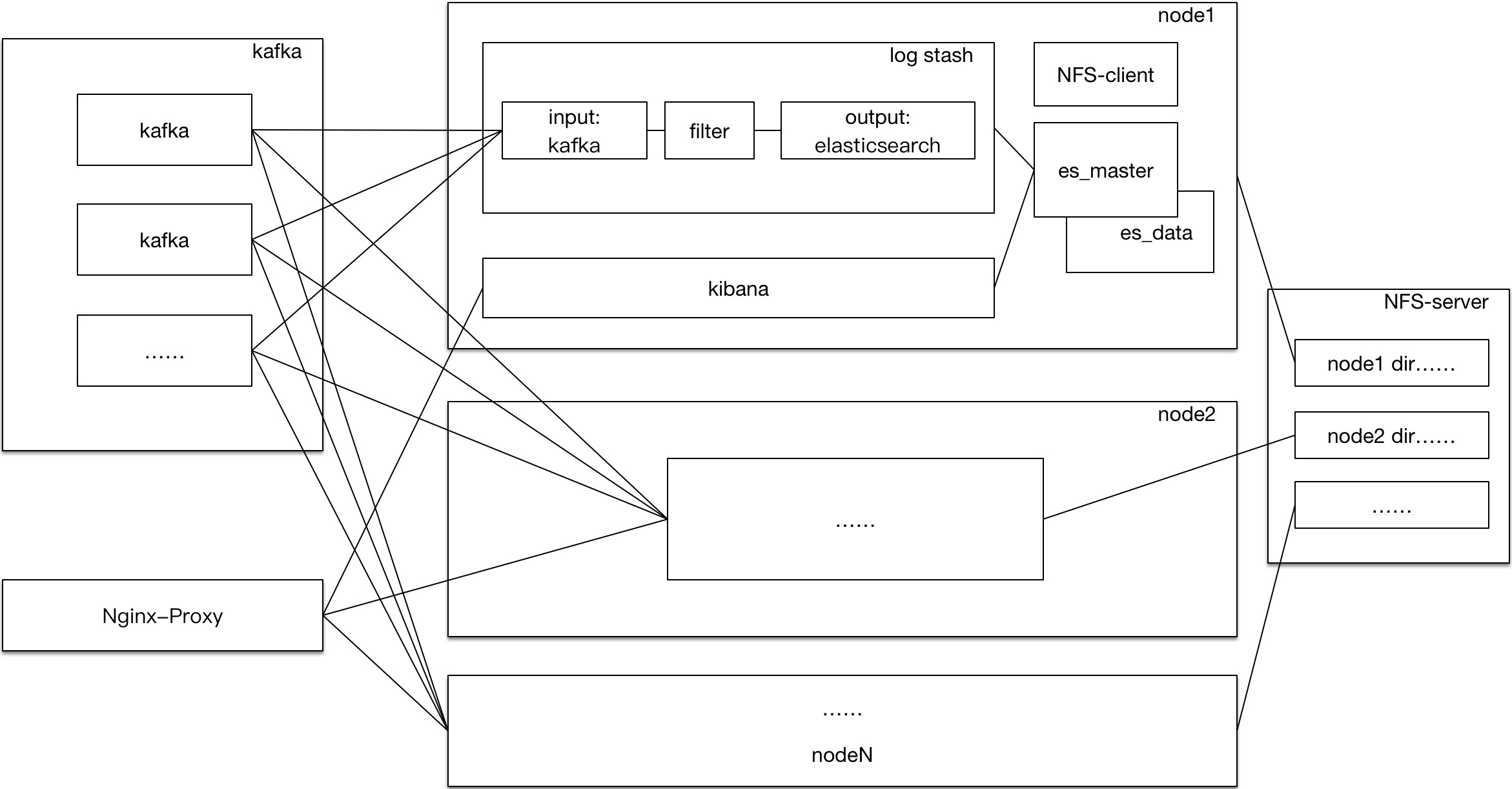
机器限制,所以对elk的部署做了四件主要工作:
将elk制作了imgae,为了支持多节点部署,需要相应名字的指定环境变量来传递集群成员的信息,启动时将修改elasticsearch和logstash配置,另外image启动之后均使用宿主机的ip
限制了ES container运行机host的5601端口,防止脚本注入攻击,只开放了对若干ip的访问权限,另外单独部署了nginx-proxy负载均衡地访问kibana界面,加了登陆验证功能
单独部署了多台机器的kafka集群,接收数据作为logstash的message输入端。kafka集群单独运维,单独调参,container可通过环境变量传入来进行启动设置。另外kafka也有单独的监控,制作了image。
多台机器开启了nfs文件映射。kafka的数据和日志,elk的数据和日志,都通过卷映射到nfs server的相应目录。由于es不再支持root启动,nfs的映射采用匿名映射方式。
Note:nfs server在此套系统中比其他节点的负载率高出5左右
Elasticsearch
配置项(摘了主要):
1 | cluster.name: logging |
http://${elasticsearch_ip}:9200/_cluster/health?pretty
可以读取集群状态
Elasticsearch不再支持root权限,需要使用自定义用户启动。
Logstash
配置项(摘了主要):
1 | node.name: "logstash" |
1 | input { |
Kibana
配置项(摘了主要):
1 | server.host: "0.0.0.0" |
http://${kibana_ip}:5601/status 可以读本机状态。
Improvement
优化主要需要在五方面上下功夫:操作系统limit,内存,Cpu(为处理开多线程),IO,JVM
1 | ## 操作系统limit |
Usage
参考官网: elastic
主要使用kibana和elasticsearch API
kibana作图:kibana dashboard
elasticsearch query:elasticsearch query